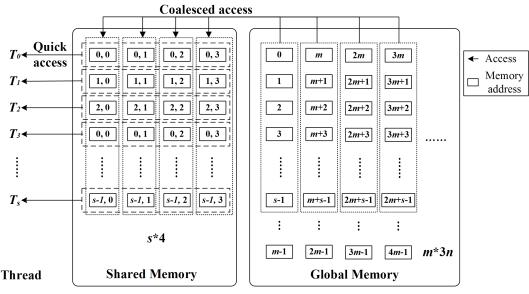
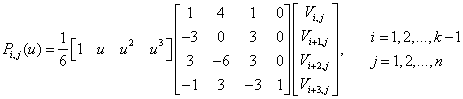2. Overall visualization framework
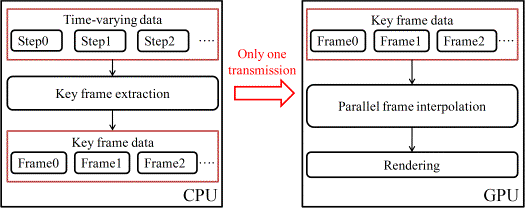
The overall framework of high-speed visualization of massive time-varying data resulted from a large-scale structural dynamic analysis is illustrated in Figure 1. In this framework, data transmission from the host memory to the GPU memory is implemented once only before rendering. Hence, instead of slow data transmission, key frame extraction and parallel frame interpolation will dominate the rendering efficiency for time-varying data visualization.
Three platforms are used for this framework: (1) a graphics platform, (2) a software development platform and, (3) a hardware platform. An open-source graphics engine, OSG (OpenSceneGraph), is adopted as the graphics platform to implement some in-depth visualization developments [33]. The CUDA (Compute Unified Device Architecture) platform, being the most widely used in general GPU computing development, is adopted as the software development platform [34]. Accordingly, a video card supporting CUDA, e.g., Quadro FX 3800 (192 cores, 1GB memory, widely used in desktop computers), is adopted as the hardware platform. The osgCompute library developed by the University of Siegen [35] is used to integrate OSG and CUDA. Using these platforms, the entire process of visualization can be fully controlled from software to hardware, which provides a convenient foundation for solving the visualization problems for massive time-varying data.
3. Clustering-based key frame extractions
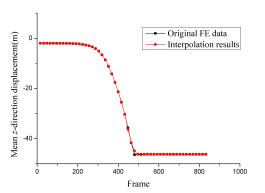
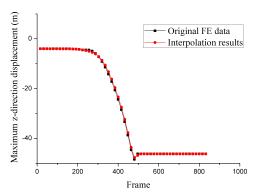
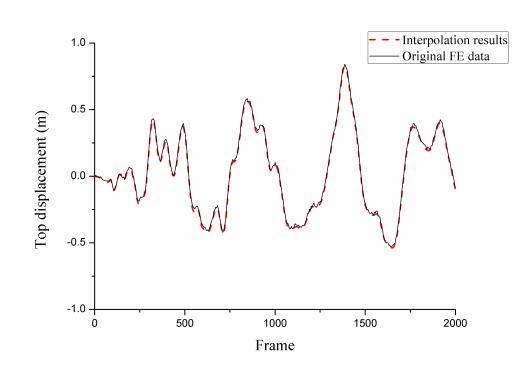
The time-varying data of a structural dynamic analysis includes displacements, stresses, velocities, etc. Note that this study focuses on the nodal displacement data which are used as references for visualizing other types of data. The proposed extraction algorithm divides the entire process of movement into several sub-processes (i.e., clusters). Although sub-processes are quite different from each other, there is a significant similarity within each sub-process; thus a few key frames are adequate to represent the entire sub-process. The first, middle and last frames of each cluster are selected as the key frames, which correspond to the beginning, developing and finishing stages of the sub-processes, respectively.
The purpose of key frame extraction is to satisfy the constraints of a GPU memory, i.e., the total volume of key frames must be lower than that of a GPU memory. As mentioned above, a cluster can produce three key frames (two boundaries and one middle), however two adjacent clusters share the same boundary frame. Defining the number of clusters and that of key frames as Nc and k, respectively, we have k = 2Nc + 1. The number and volume of the total frames are defined as Nf and Vf, respectively. The variable Vv represents the volume of the GPU memory. Given that the data volume of the key frames kVf / Nf should be smaller than Vv, the maximum of Nc can then be calculated by Eq. (1):
|
|
(1) |
The larger Nc
is, the larger k is, which implies that more key frames are produced
for a more complete visualization. Theoretically, ![]() should be aimed
for. However, Nc does not reach
should be aimed
for. However, Nc does not reach ![]() in reality because
the GPU memory also stores other required data (e.g., structural model and
textures), namely the static data which do not change with different time
steps. The GPU memory size used for static data varies for different rendering
problems and different GPU platforms, which can be measured by using some
memory monitoring software (e.g., RivaTuner [36]). In this study, the value
of Nc is approximately 0.8
in reality because
the GPU memory also stores other required data (e.g., structural model and
textures), namely the static data which do not change with different time
steps. The GPU memory size used for static data varies for different rendering
problems and different GPU platforms, which can be measured by using some
memory monitoring software (e.g., RivaTuner [36]). In this study, the value
of Nc is approximately 0.8 ![]() for the case studies (presented in Section 5) and
the specified hardware platform (see Section 2). In other cases (e.g., in
which extreme large texture is required), however, an optimal value for Nc
should be calculated based on the measurement using RivaTuner or other software
with similar functions.
for the case studies (presented in Section 5) and
the specified hardware platform (see Section 2). In other cases (e.g., in
which extreme large texture is required), however, an optimal value for Nc
should be calculated based on the measurement using RivaTuner or other software
with similar functions.
The coordinates of all graphical vertices in each frame are available from the structural dynamic analysis. In the ith frame, the vector consisting of all vertices is defined as a frame vector, i.e., Xi. If the total number of vertices is n, the distances between two different frame vectors [37], i.e., Xi and Xj, can be calculated by Eq. (2):
|
|
(2) |
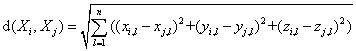
where xi,l, yi,l and zi,l are the 3D coordinates of the lth vertex in the ith frame.
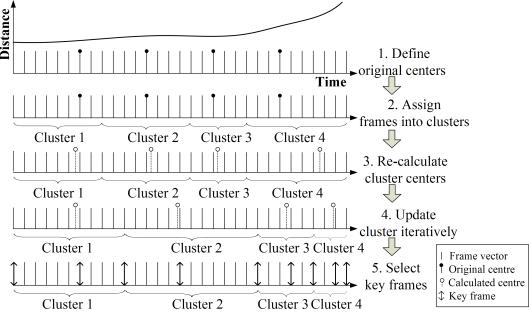
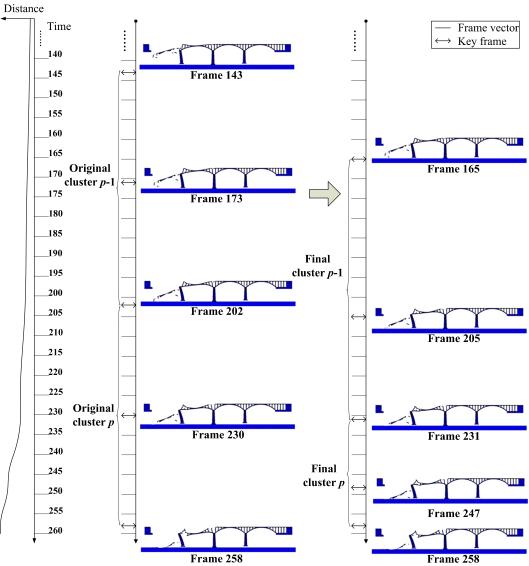
The distance calculated in Eq. (2), which represents the degree of movement of the structure between two frames, is selected as the criterion of clustering. Based on this criterion, the proposed key frame extraction algorithm is outlined as follows:
(1) Define the original cluster centers
Nc frame vectors,
![]() , j = 1, 2, ��Nc, are extracted
from the N frame vectors at the same time interval as the original
cluster centers.
, j = 1, 2, ��Nc, are extracted
from the N frame vectors at the same time interval as the original
cluster centers.
(2) Assign frames into clusters
Between the two adjacent clusters, a frame vector must be assigned to the cluster with the shorter distance to its center.
(3) Re-calculate cluster centers
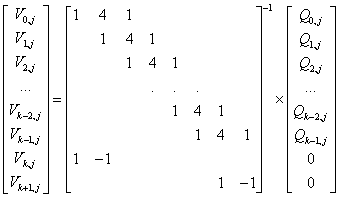
After all frames are assigned to the corresponding clusters, the cluster centers are re-calculated according to Eq. (3):
|
|
(3) |
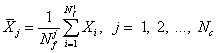
where
![]() is the number
of frame vectors in the jth cluster.
is the number
of frame vectors in the jth cluster.
![]() represents the calculated center of the jth
cluster. It is noted that
represents the calculated center of the jth
cluster. It is noted that
![]() is a mean vector and is possibly not a real
frame vector.
is a mean vector and is possibly not a real
frame vector.
(4) Update the cluster iteratively
Repeat Steps (2) �C (4) until all the cluster
centers, ![]() , do not alter any more.
, do not alter any more.
(5) Select key frames
For
each cluster, the boundary frames and the frame that is the closest to the
cluster center ![]() are selected
as the key frames.
are selected
as the key frames.
The above process of extracting key frames is illustrated in Figure 2. The horizontal axis refers to a time scale, whereas the vertical axis represents the distances of different frame vectors. Thus, the curve in Figure 2 describes the change in distances. The larger the slope of this curve, the more significant the movements are. Figure 2 shows that more key frames are extracted for significant changing phases, and vice versa, which can better demonstrate the characteristics of a structural dynamic process.