|
Acknowledgements
The first two
authors are grateful for the financial support received from the National
Key Technology R&D Program (No. 2015BAK14B02), the National Natural Science
Foundation of China (No. 51578320), National Non-profit Institute Research
Grant of IGP-CEA (Grant No: DQJB14C01) and the European Community's Seventh
Framework Programme, Marie Curie International Research Staff Exchange Scheme
(IRSES) under grant agreement n�� 612607. The third author would like to acknowledge
the chair (visiting) professorship sponsored by Tsinghua University which
greatly helps facilitate this research during his visit to the university.
References
[1] Reyners M. Lessons
from the destructive Mw 6.3 Christchurch, New Zealand, earthquake. Seismol
Res Lett 2011; 82(3): 371�C372.
[2] Tyagunov S, Grunthal
G, Wahlstrom R, Stempniewski L, Zschau J. Seismic risk mapping for Germany.
Nat Hazard Earth Sys 2006; 6: 573�C586.
[3] Korkmaz KA. Seismic
safety assessment of unreinforced masonry low-rise buildings in Pakistan and
its neighborhood. Nat Hazard Earth Sys 2009; 9: 1021�C1031.
[4] Steelman J, Hajjar
J. Influence of inelastic seismic response modeling on regional loss estimation.
Eng Struct 2009; 31: 2976�C2987.
[5] Tang BX, Lu XZ,
Ye LP, Shi W. Evaluation
of collapse resistance of RC frame structures for Chinese schools in seismic
design categories B and C.
Earthq Eng Eng Vib 2011; 10: 369�C377.
[6] Yamashita T, Kajiwara
K, Hori M. Petascale computation for earthquake engineering. Comput Sci Eng
2011; 13: 44�C49.
[7]
Xu Z, Lu XZ, Guan H, Han B, Ren AZ. Seismic damage simulation in urban areas
based on a high-fidelity structural model and a physics engine. Nat Hazards
2014; 71: 1679�C1693.
[8]
Xiong C, Lu XZ, Lin XC, Xu Z, Ye LP, Parameter determination and damage assessment
for THA-based regional seismic damage prediction of multi-story buildings.
J Earthq Eng 2016. DOI: 10.1080/13632469.2016.1160009.
[9]
Xiong C, Lu XZ, Guan H, Xu Z, A nonlinear computational model for regional
seismic simulation of tall buildings. B Earthq Eng 2016; 14(4): 1047�C1069.
[10]
Xu Z, Lu XZ, Guan H, Tian Y, Ren AZ, Simulation of earthquake-induced hazards
of falling exterior non-structural components and its application to emergency
shelter design. Nat Hazards 2016; 80(2): 935�C950.
[11]
Xiong C, Lu XZ, Hori M, Guan H, Xu Z, Building seismic response and visualization
using 3D urban polygonal modeling. Automat Constr 2015; 55: 25�C34.
[12]
Lu X, Lu XZ, Guan H, Ye LP. Collapse simulation of reinforced concrete high-rise
building induced by extreme earthquakes. Earthq Eng Struct D 2013; 42: 705�C723.
[13] FEMA. Seismic performance
assessment of buildings volume 1 - Methodology. Washington, DC, 2012.
[14] FEMA. Seismic performance
assessment of buildings volume 2 - Implementation guide. Washington, DC, 2012.
[15]
Zeng X, Lu XZ, Yang T, Xu Z, Application of the FEMA-P58 methodology for regional
earthquake loss prediction. Nat Hazards 2016. DOI: 10.1007/s11069-016-2307-z.
[16] FEMA. Multi-hazard
loss estimation methodology, earthquake model, HAZUS�CMH 2.1 technical manual,
Washington, DC, 2012.
[17] FEMA. Multi-hazard
loss estimation methodology HAZUS�CMH 2.1 advanced engineering building module
(AEBM) technical and user��s manual, Washington, DC, 2012.
[18]
Lu XZ, Han B, Hori M, Xiong C, Xu Z. A coarse-grained parallel approach for
seismic damage simulations of urban areas based on refined models and GPU/CPU
cooperative computing. Adv Eng Softw 2014; 70: 90�C103.
[19] Wen-Mei WH. GPU
computing gems emerald edition. Morgan Kaufmann, Burlington, MA, 2011.
[20] Stone JE, Phillips
JC, Freddolino PL, Hardy DJ, Trabuco LG, Schulten K. Accelerating molecular
modeling applications with graphics processors. J Comput Chem 2007; 28: 2618�C40.
[21] Weldon M, Maxwell
L, Cyca D, Hughes M, Whelan C, Okoniewski M. A practical look at GPU-accelerated
FDTD performance. Appl Comput Electrom 2010; 25: 315�C22.
[22] Zheng J, An X,
Huang M. GPU-based parallel algorithm for particle contact detection and its
application in self-compacting concrete flow simulations. Comput Struct 2012;
112�C113: 193�C204.
[23] Cai Y, Wang GP,
Li GY, Wang H. A high performance crashworthiness simulation system based
on GPU. Adv Eng Softw 2015; 86: 29�C38.
[24] Rodrigues W, Pecchia A, Lopez M, Auf der Maur
M, Di Carlo A. Accelerating atomistic calculations of quantum energy eigenstates
on graphic cards. Comput Phys Commun 2014; 185(10): 2510�C2518.
[25] Buatois L, Caumon G, Levy B. Concurrent
number cruncher: a GPU implementation of a general sparse linear solver. International
Journal of Parallel, Emergent and Distributed Systems 2009; 24(3): 205�C223.
[26] Coulouris, G, Dollimore J, Kindberg
T, Blair G. Distributed systems: concepts and design (5th edition). Addison-Wesley,
Boston, MA, 2011.
[27] Xian W, Takayuki A. Multi-GPU performance
of incompressible flow computation by lattice Boltzmann method on GPU cluster.
Parallel Comput 2011; 37(9): 521�C535.
[28] Chen Y, Cui X,
Mei H. Large-scale FFT on GPU clusters. Proceedings of the 24th ACM International
Conference on Supercomputing, ACM, New York, NY, 2010.
[29] Cevahir A, Nukada
A, Matsuoka S. High performance conjugate gradient solver on multi-GPU clusters
using hypergraph partitioning. Comput Sci Res Dev 2010; 25(1-2): 83�C91.
[30] Hassan AH, Fluke
CJ, Barnes DG. A distributed GPU-based framework for real-time 3D volume rendering
of large astronomical data cubes. Publ Astron Soc Aust 2012; 29(3): 340�C351.
[31] Okamoto T, Takenaka
H, Nakamura T, Aoki T. Large-scale simulation of seismic-wave propagation
of the 2011 Tohoku-Oki M9 earthquake. Proceedings of the International Symposium
on Engineering Lessons Learned from the 2011 Great East Japan Earthquake,
Tokyo, Japan, 2012.
[32] Wang LZ, Laszewski
G, Kunze M, Tao J, Dayal J. Provide virtual distributed environments for grid
computing on demand. Adv Eng Softw 2010; 41(2): 213�C219.
[33] Wijerathne M, Hori M, Kabeyazawa T, Ichimura
T. Strengthening of parallel computation performance of integrated earthquake
simulation. J Comput Civil Eng 2013; 27:
570�C573.
[34] BOINC. BOINC
project governance, http://boinc.berkeley.edu/trac/wiki/Project-Governance,
2014.
[35] Hadoop. What
is Apache Hadoop, http://hadoop.apache.org/, 2014.
[36] HTCondor. http://research.cs.wisc.edu/htcondor/, 2014.
[37] Yang CF, Li HJ,
Rezgui Y, Petri I, Yuce B, Chen BS, Jayan B. High throughput computing based
distributed genetic algorithm for building energy consumption optimization.
Energ Buildings 2014; 76: 92�C101.
[38] Guba S, Őry
M, Szeber��nyi I. Harnessing wasted computing power for scientific computing.
Large-Scale Scientific Computing, Springer Berlin Heidelberg, Berlin, Germany,
2014.
[39] OpenSees. http://opensees.berkeley.edu/, 2014.
[40] NVIDIA. CUDA
Programming Guide. http://docs.nvidia.com/cuda, 2014.
[41] CuSPSolver, http://opensees.berkeley.edu/wiki/index.php/Cusp, 2014.
[42] Zheng GB. Achieving
high performance on extremely large parallel machines: performance prediction
and load balancing. University of Illinois at Urbana-Champaign, 2005.
[43] Nickolls J, Buck
I, Garland M, Skadron K. Scalable parallel programming with CUDA. Queue 2008;
6(2): 40�C53.
[44]
Lu XZ, Xie LL, Guan H, Huang YL, Lu X. A shear wall element for nonlinear
seismic analysis of super-tall buildings using OpenSees. Finite Elem Anal
Des 2015; 98: 14�C25.
[45] McKenna F. OpenSees:
a framework for earthquake engineering simulation. Comput Sci Eng 2011; 13(4):
58�C64.
[46] McKenna F. Introduction
to OpenSees, http://www.slideshare.net/openseesdays/d1-001-005
mckennaosdpt2014,
Sep 10, 2014.
[47] Marques R, Lourenço
PB. Unreinforced and confined masonry buildings in seismic regions: validation
of macro-element models and cost analysis. Eng Struct 2014; 64: 52�C67.
[48] Cali�� I, Marletta
M, Pant�� B. A new discrete element model for the evaluation of the seismic
behaviour of unreinforced masonry buildings. Eng Struct 2012; 40: 327�C338.
[49] Cali�� I, Pant��
B. A macro-element modelling approach of infilled frame structures. Comput
Struct 2014; 143: 91�C107.
[50] Jokhio GA, Izzuddin
BA. A dual super-element domain decomposition approach for parallel nonlinear
finite element analysis. International Journal of Computational Science and
Engineering 2015; 16(3): 188�C212.
[51] Jokhio GA, Izzuddin
BA. Parallelisation of nonlinear structural analysis using dual partition
super elements. Adv Eng Softw 2013; 60-61:81�C88.
Figure Captions
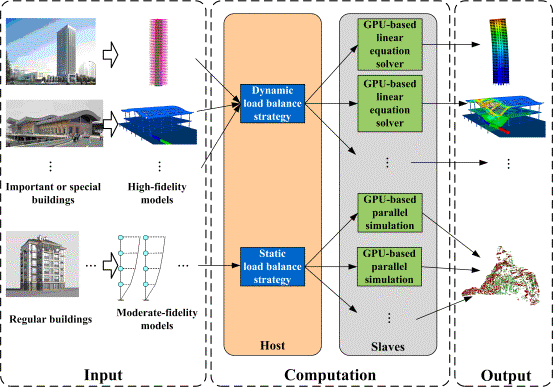
Fig. 1 Framework for simulating regional seismic damage with multi-fidelity
models
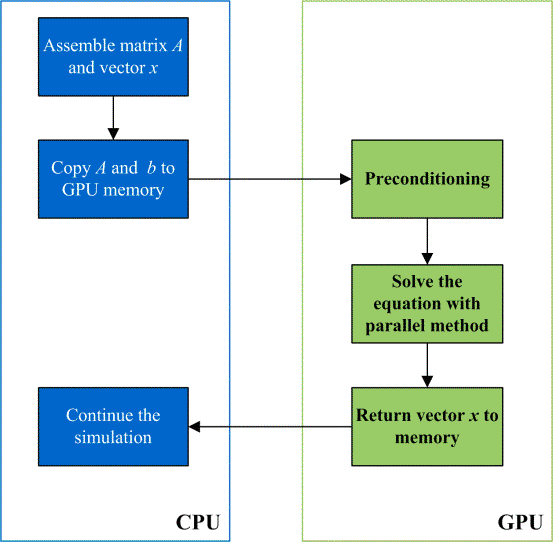
Fig. 2 Method of linear equations solving based on GPUs
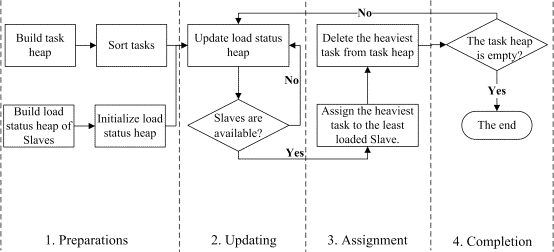
Fig. 3 Flow chart of the proposed dynamic load balancing strategy
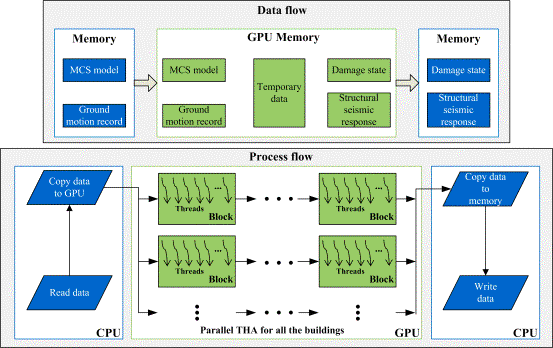
Fig. 4 A GPU-based parallel simulation method for the MCS models
Fig. 5 High-fidelity model of a tall building
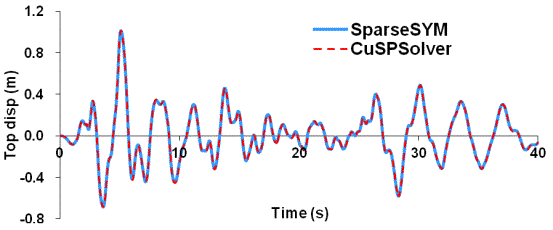
Fig. 6 Comparison of the time-history top displacements in the two different
platforms
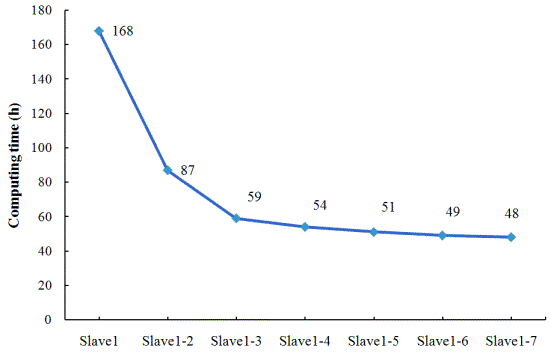
Fig. 7 Relationship between computing time and number of Slaves
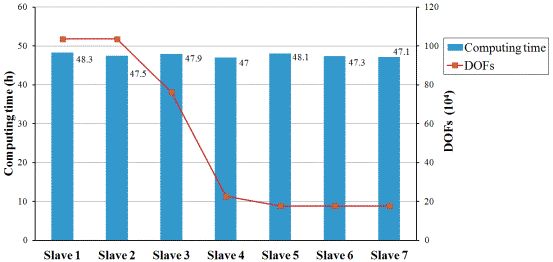
Fig. 8 Computing time for each Slave in the high-fidelity simulation
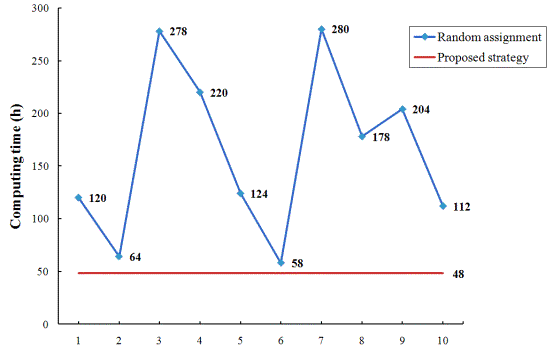
Fig. 9 Comparisons between the proposed strategy and the ten random assignments
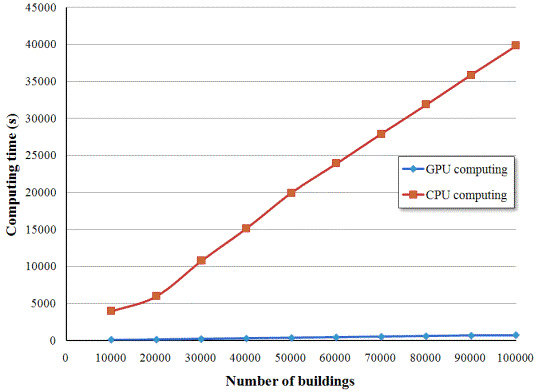
Fig. 10 Comparison between the proposed GPU computing and CPU computing
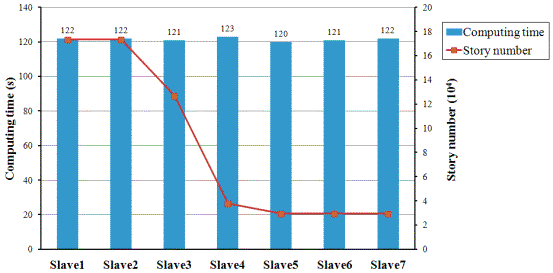
Fig. 11 Computing time for each Slave in the moderate-fidelity simulation
Fig. 12 Seismic damage states in a virtual city (different colors represent
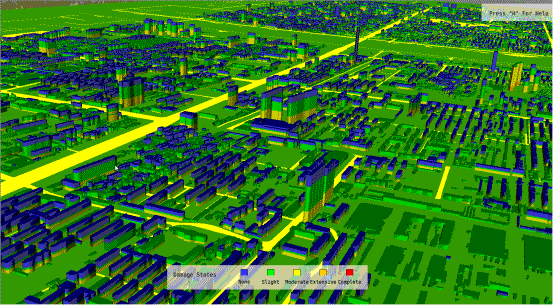
different damage states at different stories)
Table Captions
Table 1. Implementation of the proposed strategy using HTCondor
Table 2 Hardware configuration of the computational framework
|